软件截图:
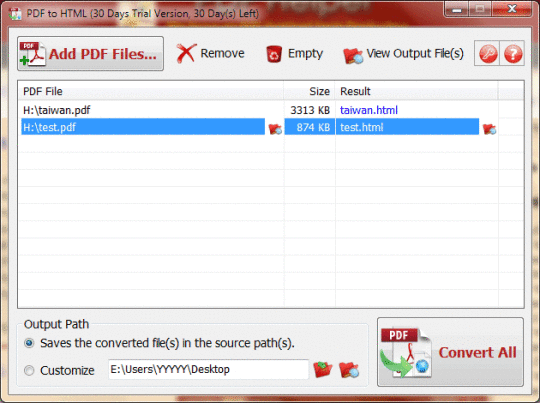
PDF到HTML被用于快速转换PDF文件在批处理模式下的HTML网页。它的工作原理没有安装Adobe Acrobat或Adobe Reader,并具有友好的人机界面,体积小,准确,快速的转换能力。它保留了原来的文字,图片,格式和布局在输出HTML文件。此外,PDF到HTML支持转换有一些限制,如“内容复制”,“保存为文本”的PDF文件,“页面提取”是不允许的。如果你想要发布的PDF内容在网络上的HTML网页,它可能是有用
什么在此版本中是新的:
支持通过拖放和拖放添加PDF文件到列表中。增加了对组织的团队许可证。转换的HTML网页无法显示图片时将PDF文件有一个非英语文件名
要求:
.NET 2.0
限制:
30天试用
评论没有发现